Tana: 解放笔记困境的终极利器
2023 / 11 / 25
我以前曾经是一个Roam Research的使用者,直到陷入困境:在以前的使用中,我过于重视表面的链接,而无法实现深层链接,导致字义需要被链接在表层句式中,含义则会被丢失。转而使用 Tana 一年后,我成为了 Tana 的忠实粉丝。
我最喜欢的 Tana 的几个功能
Contextual reference
这是笔记引用的一个变种。和普通的引用相比,引用笔记会完全基于被引用的笔记的语境下,获得被引用笔记页面中的独立内容显示,而不是简单的链接。

Field 自动补全
层级式节点能够共享相同 Field 字段。举个例子,如果 “note” 的“belong to:” 字段非空,那么在这个 “note” 节点下,新建一个“question” supertag 节点后,这个节点的"belong to:" 字段会自动赋值。因为我在 “belong to:” 中设置了自动赋值:如果父节点某个字段且字段非空下,子节点的字段能自动赋值。
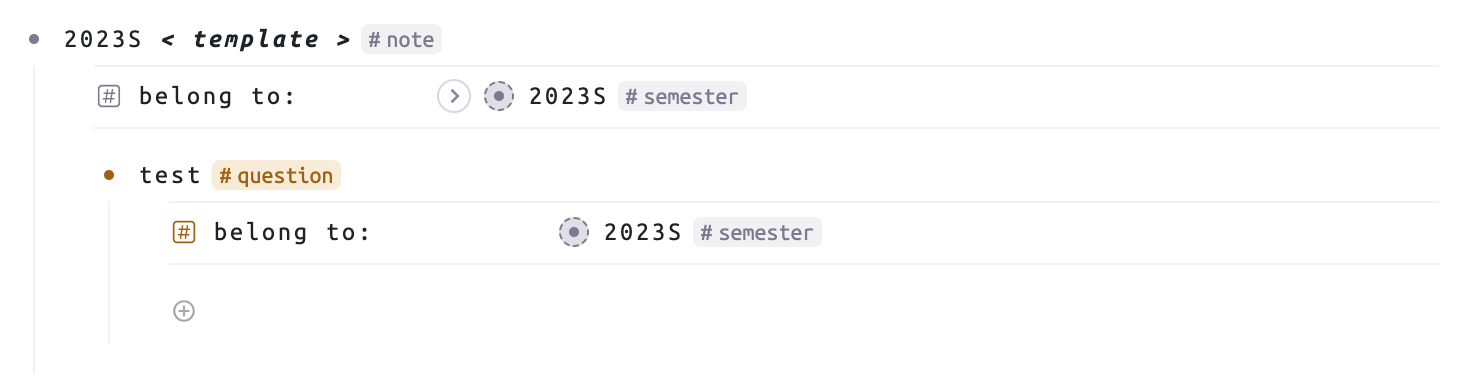
Supertag 模版
让我能够快速应用一致性结构,并进行修改。它非常灵活且强大。对于使用相同 supertag 的节点,可以应用相同的模版。结合上述的功能,可以实现更高效的操作。举个例子,我可以在针对课程的supertag模版,添加对于笔记和问题的查询节点: "node-query" 和 "question-query",这样每新建一个课程节点,就能得到相同的结构。
似是而非的节点层级结构
在使用 Roam Research 和 Obsidian 时,我对笔记的层级结构有一定的强迫症。我曾经纠结于将书籍作为当日笔记的子节点,还是为每本书创建一个新的页面。但是使用 Tana 后,我不再有这样的顾虑和强迫性思考,只需要使用 supertag,无需担心是用 [[]] 还是 @ 来查找笔记内容。
关于我现在如何使用Field
我已经使用了 Tana 一年多了。但仍然在不断优化我的笔记结构。当过去几下的笔记被用上场时,我会思考如何能够进一步让自己利用并展示笔记/知识中的亮点。也就是说,我会这样发问,我记下这个笔记,未来的我怎么能找到它呢?这个笔记又如何发挥作用呢?
以前的课程 supertag 中没有 question-query。而我想要查看课程笔记中到底遇到过怎么样的问题,又得到过怎么样的解释时,一度很迷糊,不知道如何实现这样的功能。后来将 “question” 的supertag模版改动后,让所有的问题都能直接指向课程本身,而不是更宽泛的主题概念或者课程笔记,这样我就能在课程页面,实时预览问题列表。
在 Zettlekasten 卡片流行的时候,个人知识管理系统被赋予了信息凝练和卡片链接的标签,而个人需要实现从原文到知识体系的消化和表达。这样的体系,是在追求同层级笔记信息粒度的一致化,这些笔记的核心必须是源自笔记。所以很多知识博主展现了如何将知识原子化的技巧。
然而, Tana 让我更重视不同层级知识在信息表达上的一致化特征,这一突破的关键在于 "Field" 概念。一开始我以为是 Supertag 容纳 Field,是一个信息维度有多种表达维度;但是,Tana 实现的理念要更高一级,多个 Supertag 共同拥有同一个 Field,也就是多种信息维度拥有同一个表达维度。比如说,一篇文章、一本书、一个摘抄或一部电影,共同拥有同一个表达维度,并且在这个一个表达维度下拥有共同的核心。让我再次细化这个例子,这几个信息维度都能表达创作主题(表达维度),而它们的创作维度刚刚好都是“个人知识管理系统”。
关于我现在如何使用Query
为了让自己应用知识而记录信息。抱有这样的目的,会反过来影响记笔记时自己如何把控重点,以及如何标记笔记。
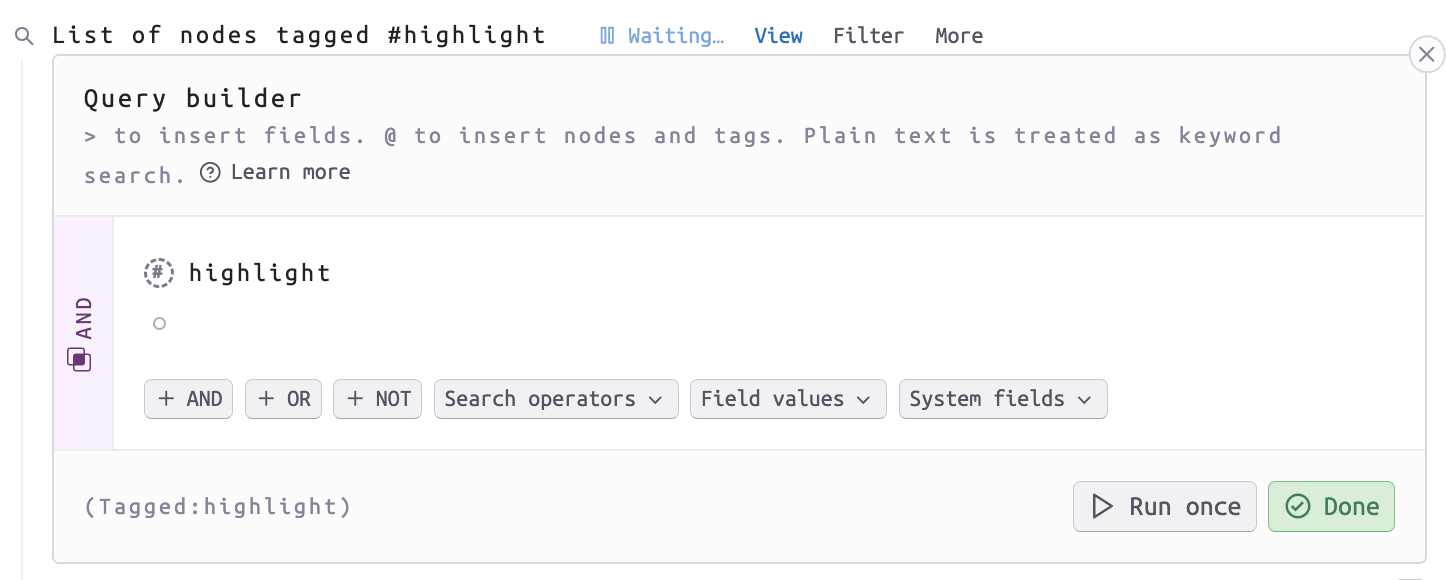
在 Tana 中标记笔记,就是让笔记具有可检索性,让自己在未来需要用到某一些笔记的时候,通过简单地叠加不同的信息,查询出满足要求的笔记。纯文本当然具有可检索性,但 Tana 能在Query 中 叠加 supertag 和 field 等信息,让笔记节点的查询更具有指向性。
另外,Tana 的 Query 具有不错的用户交互界面以及丰富的查询选择,能够适应不同用户的笔记处理习惯。
后记
我并不会把所有写下的内容都放Tana,更多的是笔记因我的目的不同而各自分道扬镳——这种目的主要是出自于“我想再看到它的频率”。如果我想在一段时间内有规律地重复刷,以增强我对笔记的理解记忆,我会使用 Anki;如果我想要某天笔记能让我灵机一动,我会想要使用 Flomo。但如果我想要看见一个笔记的结构性统合,我会选择使用 Tana写笔记。
是的,我爱它。